





Resources
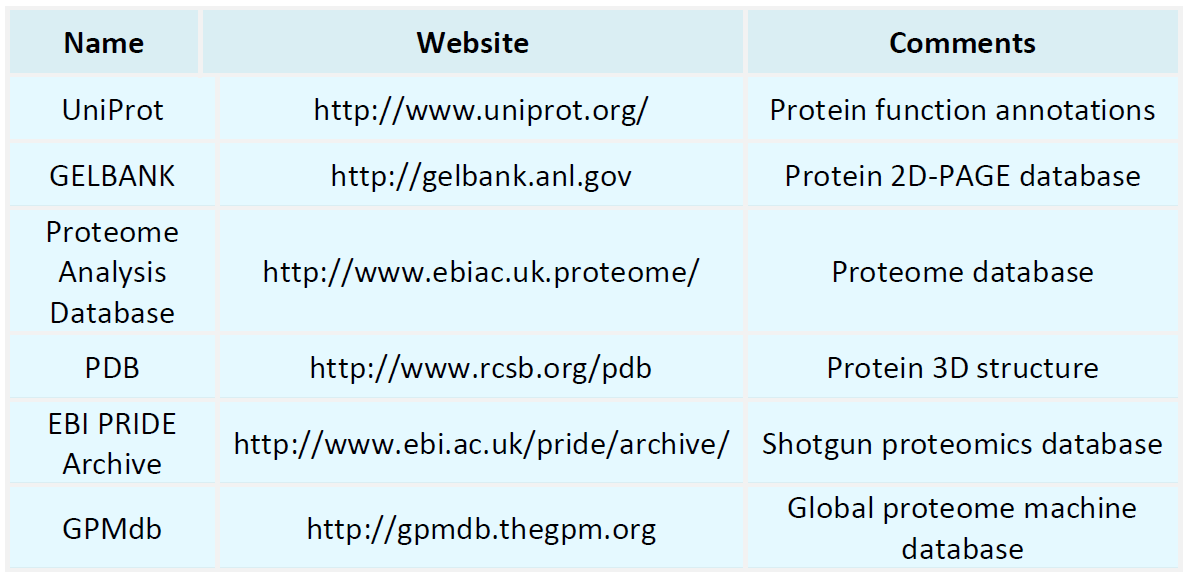
Proteomics Databases
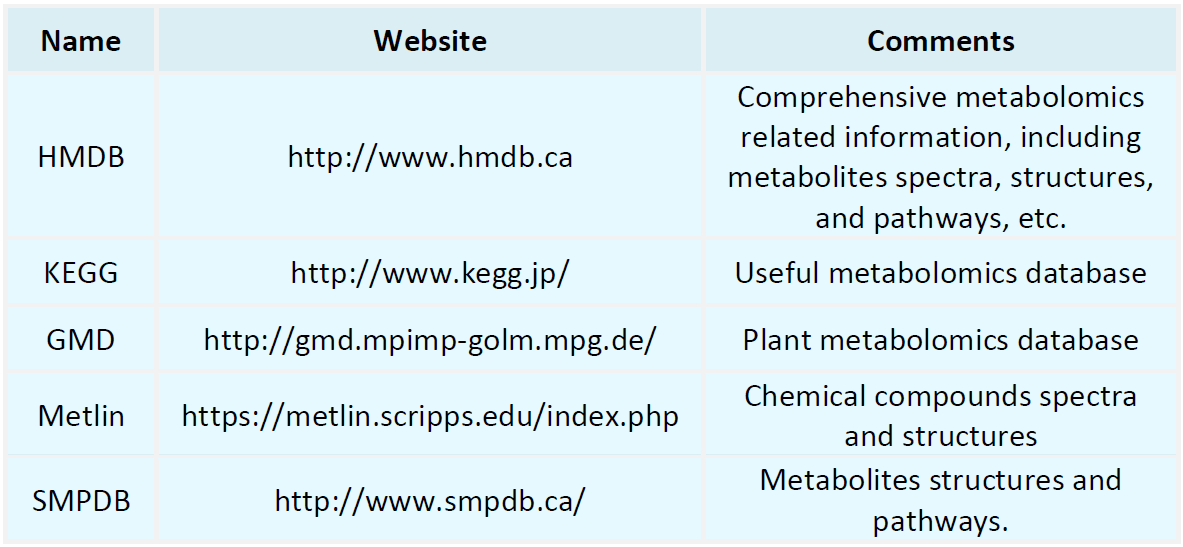
Metabolomics Databases
-
Immunoprecipitation is an important experimental technique used in the field of biopharmaceuticals to study protein interactions. In this process, antibodies bind specifically to target proteins, and the complexes are then separated by precipitation techniques for further analysis. However, due to the complexity and specificity of the samples, immunoprecipitation experiments may face challenges such as low purity and non-specificity.
-
• Glycosylation Modification Omics Analysis From Qualitative to Quantitative
Protein is one of the most important functional molecules in cells, and studying protein modification is of great significance for a deeper understanding of its biological function. Among them, glycosylation modification, as a common and important way of protein modification, has attracted much attention from researchers. Glycomics is a systematic method for studying protein glycosylation modification. Through this method, we can fully understand the types, locations, and quantities of glycosylation m......
-
• Optimizing Sample Preparation Steps for Label-Free Semi-Quantitative Chemical Proteomics
Label-free semi-quantitative proteomics is an important proteomics method that can quantitatively analyze the differential expression of proteins in cells or tissues. In this process, sample preparation is a key factor affecting the accuracy of the results. Optimizing sample preparation steps can maximize the reliability and repeatability of experiments. Sample Pretreatment In label-free semi-quantitative proteomics, sample pre-treatment is the first step to consider.
-
• The Importance and Application of P-value Adjustment in Differential Analysis of Proteomics
Proteomics is a scientific field that studies the complete set of proteins, their structures, and functions in organisms. In proteomics research, differential analysis is a critical step that helps us identify the differences in protein expression between different samples. The p-value is a commonly used statistical indicator in differential analysis, which can evaluate whether the observed difference is statistically significant.
-
• The Prospects of Label-Free Proteomics in Disease Research
Proteomics, as an important branch of the field of bioproduct proteomics, is committed to comprehensively analyzing the composition and function of proteins in cells. Label-free proteomics, as a emerging technology, has emerged in the field of disease research in recent years. Its unique advantages make it a powerful tool for revealing the physiological mechanisms of diseases, discovering new therapeutic targets, and achieving personalized medicine. Label-free proteomics is a proteomics method that ......
-
• Methods and Principles of Membrane Protein Glycosylation Analysis
Glycosylation of membrane proteins is a crucial post-translational modification process that involves the binding of proteins on the cell membrane with sugar molecules. This modification process plays a significant role in cell signaling, cell recognition, cell adhesion, and protein stability. Types of Membrane Protein Glycosylation Membrane protein glycosylation can be divided into two types: N-glycosylation and O-glycosylation. N-glycosylation occurs on the nitrogen atoms of amino acids in protein......
-
• How to Analyze Glycosylation Sites
Proteins are among the most important functional molecules in cells. To enhance their function and diversity, cells carry out various modifications on proteins. Among these, glycosylation is a common and important protein modification method, which regulates protein function and stability by adding sugar molecules. Accurate localization and analysis of glycosylation sites are crucial for a deep understanding of protein biological functions, understanding disease mechanisms, and play a key role in the ......
-
• Multiple-Level Analysis of Protein Phosphorylation Regulation on Plant Growth and Development
Every organism is a minuscule universe composed of millions of proteins, with their interactions determining the course of life. Among these proteins, protein phosphorylation, as one of the most common post-translational modifications, plays a vital role in regulating biological activities. In life processes, proteins need to function at the appropriate time and place. Protein phosphorylation is a vital means of controlling protein function. It adjusts the conformation of proteins by removing or add......
-
• The Impact of Mass Spectrometry on the Discovery and Validation of Biomarkers
Biomarkers refer to molecular features that can indicate specific physiological states, disease progressions, or drug responses. The discovery and validation of appropriate biomarkers are of significant importance for disease diagnosis, treatment monitoring, and drug development. Mass spectrometry, as an efficient, accurate, and sensitive analytical method, has become an essential tool in the field of biomarker research. Discovery and Significance of Biomarkers 1. Definition of Biomarkers Biomarker......
-
• TMT Technology in Mass Spectrometry
TMT (Tandem Mass Tag) technology is a major method for studying protein quantification. This technology realizes quantification by labeling isotopes at the protein or peptide level and using mass spectrometry detection, which enables comprehensive and accurate detection of the expression levels of proteomes in biological samples. How to Analyze Proteomes with Mass Spectrometry TMT Technology In the experimental process, we first need to extract the proteins in the sample and break them down into pep......
How to order?

