





Resources
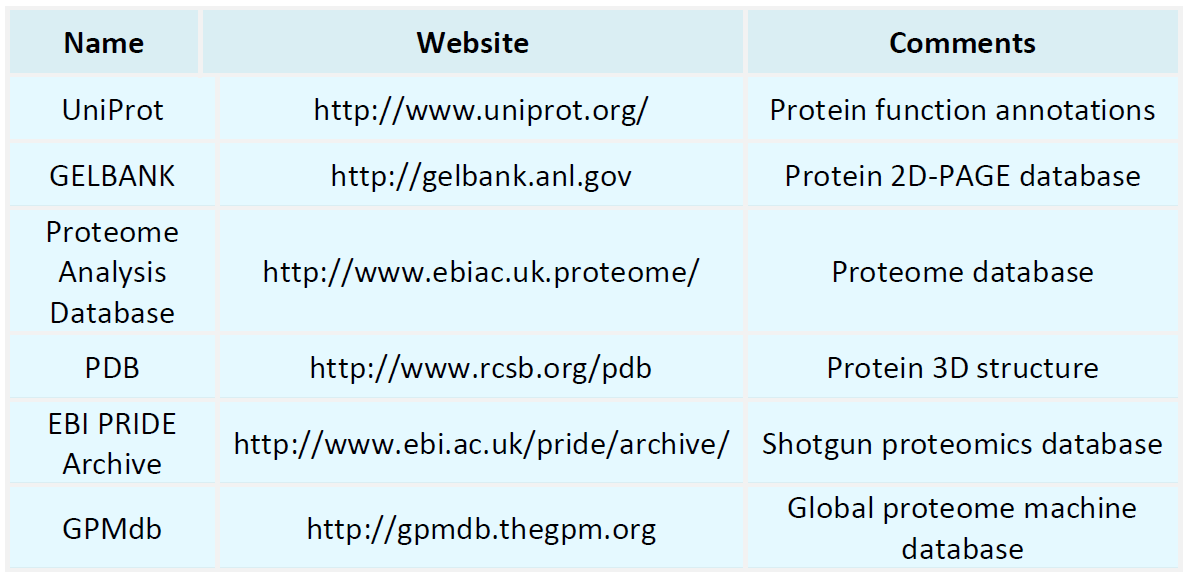
Proteomics Databases
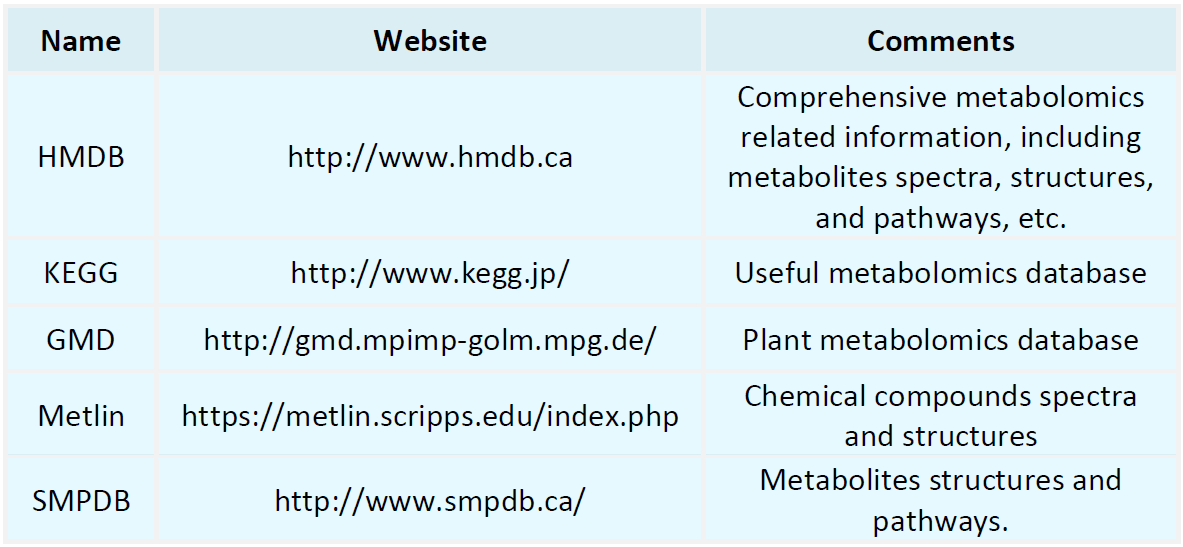
Metabolomics Databases
-
• Can Proteomics Specifically Detect the Content of a Particular Protein
Proteomics allows for the precise quantification of specific proteins. It is a multidisciplinary field that examines the expression, modification, interaction, and function of proteins. Proteomics involves comprehensive methods for the identification and quantification of proteins, including all those encoded by genes and their derivatives. Additionally, it explores how proteins influence cellular functions and biological processes. Mass spectrometry is typically employed in proteomics to assess protein....
-
• Can the P-Value for Protein Differential Analysis Be Set to 0.2
In the context of differential protein analysis, the p-value is a widely utilized metric for assessing statistical significance, indicating whether the observed discrepancies from the null hypothesis may have occurred by chance. While researchers have the autonomy to select any p-value as the significance threshold, a value of 0.05 or stricter is typically chosen in most scientific investigations. Selecting a higher p-value, such as 0.2, can elevate the risk of committing a Type I error, which involves.....
-
• How to Create a Quantitative Proteomics Heatmap
A quantitative proteomics heatmap is a visualization tool used to illustrate changes in protein abundance across different samples. Creating such a heatmap involves several steps, including data preparation, normalization, clustering analysis, and plotting. This tutorial provides a step-by-step guide for constructing such a heatmap. 1. Data Preparation To begin, a quantitative proteomics dataset is required. Typically, this dataset is organized in a tabular format, with columns representing samples, rows...
-
10x RNA sequencing represents an advanced method of droplet-based single-cell RNA sequencing that captures gene expression profiles at single-cell resolution. By isolating individual cells and encapsulating them in oil droplets, this technology leverages unique barcode labeling alongside high-throughput sequencing to conduct transcriptome analysis at the single-cell level. The capabilities of this method allow researchers to deeply investigate cellular heterogeneity and interactions, thus facilitating......
-
• Droplet-Based Single-Cell Sequencing
Droplet-based single-cell sequencing is an innovative biotechnology that facilitates high-throughput analysis of complex biological samples at the single-cell level. This technique involves the encapsulation of individual cells into microdroplets, where nucleic acid amplification and sequencing reactions occur, allowing for efficient cell isolation and independent genetic analysis. In contrast to traditional bulk sequencing methods, droplet-based single-cell sequencing provides detailed insights into ......
-
10x Genomics sequencing is a cutting-edge high-throughput sequencing technology that leverages microfluidic systems combined with innovative sequencing strategies to deliver highly detailed and accurate genomic information. The cornerstone of this technology is its capability to perform single-cell sequencing, effectively distinguishing the genomic information of individual cells from others. This single-cell resolution significantly enhances our comprehension of complex biological systems and disease......
-
• Single-Cell Sequencing Microbiome
Single-cell sequencing microbiome enables the analysis of complex microbial communities at the single-cell level. By isolating individual microbial cells and performing genomic sequencing, this technology provides an unprecedented level of detail for observing the diversity and functions of microbial ecosystems. This capability has found applications in a variety of fields, particularly in environmental science, clinical research, and biotechnology development. For instance, in human health, single-ce......
-
• Protein Structure X-Ray Crystallography
Protein structure X-ray crystallography is a technique employed to elucidate the three-dimensional structures of proteins. Since the early 20th century, following the discovery of X-rays, scientists have developed methodologies to utilize this powerful tool to explore the internal structures of protein molecules. This technology allows researchers to observe protein structures at atomic precision, which is fundamental for understanding their functions. Proteins are responsible for numerous critical ro......
-
• Single-Cell Sequencing Immune Cells
Single-cell sequencing immune cells has emerged as an innovative technology in recent years, designed to analyze the genomic, transcriptomic, or other omics data of individual immune cells. Traditional sequencing methods typically rely on mixed samples from large populations of cells, which can obscure cell heterogeneity, resulting in the loss of critical information. In contrast, single-cell sequencing immune cells overcomes this limitation. By sequencing individual cells, researchers can uncover the......
-
• Single-Cell Sequencing Technology
Single-cell sequencing technology is an advanced genomic analysis approach designed for investigating the genome, transcriptome, and epigenome of individual cells. Traditional sequencing methods typically require large numbers of cells, and the resulting data represents averages across cell populations, thus failing to capture the specific differences of individual cells. However, organisms are composed of diverse cell types, each with its unique functions and gene expression profiles. Single-cell seq......
How to order?

