





Resources
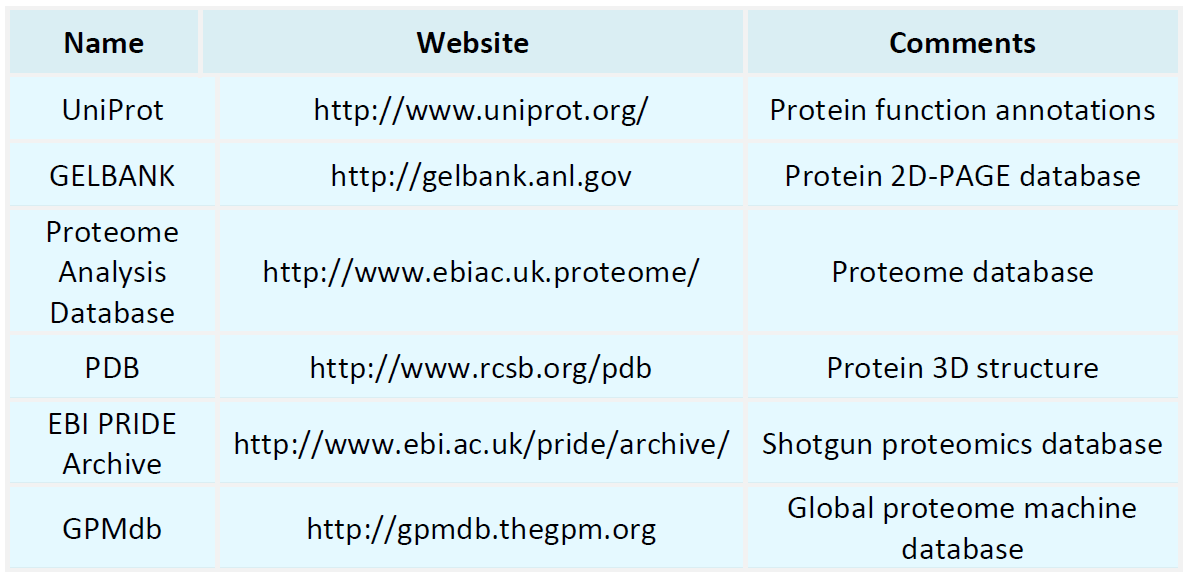
Proteomics Databases
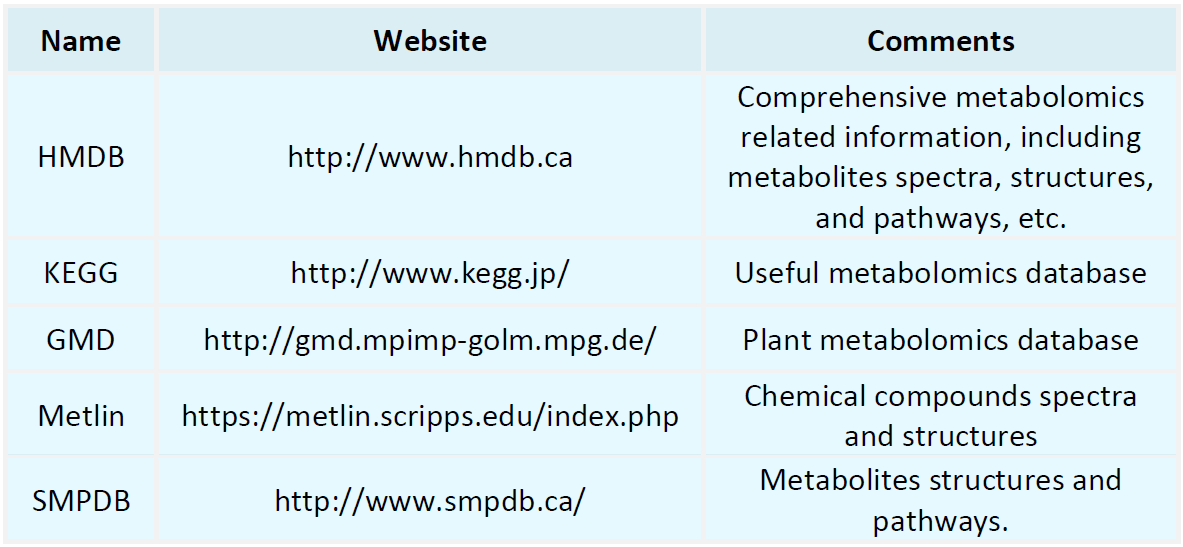
Metabolomics Databases
-
• What Is Immunoprecipitation Mass Spectrometry and When Is It Used?
Learn what IP-MS is, how it differs from Co-IP and AP-MS, and when immunoprecipitation mass spectrometry fits endogenous bait interaction projects.
-
• How to Prepare Immunoprecipitation Samples for Mass Spectrometry
Prepare IP samples for LC-MS/MS with matched isotype controls, buffer-compatible digestion, peptide cleanup, and metadata for IP-MS interaction analysis.
-
• What Is Exosome Proteomics Service and When Should You Use It?
A service guide explaining what exosome proteomics is, when to request an Exosome Proteomics Service or EV Proteomics Service, and what to confirm before submission.
-
• Extracellular Vesicle Proteomics Service: From EV Protein Profiling to Comparative Analysis
A service-oriented guide to extracellular vesicle proteomics covering EV protein profiling, comparative EV proteomics analysis, and how EV search terms map to exosome proteomics workflows.
-
• How to Choose an AP-MS Service Provider for Your Project
Compare AP-MS providers by scope, control design support, deliverables, and consultation. See what to prepare and which questions to ask before outsourcing.
-
• How to Identify High-Confidence Interactors from AP-MS Data
Learn how to rank high-confidence interactors from AP-MS using control contrast, replicate support, enrichment scoring, and validation-ready shortlist criteria.
-
• Why Are There Too Many Background Proteins in AP-MS Data?
AP-MS list overcrowded with background proteins? Learn why long contaminant-heavy lists occur and how to triage results with controls, replicates, and enrichment ranking.
-
• Why Are Known Interactors Missing from AP-MS Results?
Expected interactors missing from AP-MS? Learn why known partners may be lost during enrichment, washing, lysis, MS sampling, or filtering, and how to respond.
-
• Why Was the Bait Protein Not Detected in AP-MS?
Bait missing from AP-MS results? Learn common causes including recovery failure, tag issues, digestion problems, and MS detection limits, and what to do next.
-
• Which Controls Are Needed for an AP-MS Experiment?
Learn which controls an AP-MS experiment needs by bait format and study goal, including empty-tag, bead-only, isotype, and comparative control arms.
How to order?

